From: http://blog.law.cornell.edu/voxpop/2010/08/15/legislationgovuk/comment-page-1/#comment-19971
We had two objectives with legislation.gov.uk: to deliver a high quality public service for people who need to consult, cite, and use legislation on the Web; and to expose the UKÂ’s Statute Book as data, for people to take, use, and re-use for whatever purpose or application they wish. In particular, our aim was to show how the statute book can contribute to the growing Web of data as well as to the Web of documents.
Legislation.gov.uk replaces two predecessor services the UK government set up to provide access to legislation. The first was created by Her MajestyÂ’s Stationery Office (HMSO), later to become the Office of Public Sector Information (OPSI), which is responsible for the official publication of legislation, and the London, Belfast and Edinburgh Gazettes. The functions of HMSO have been operating from The National Archives since 2006, including the provision of public access to legislation online. HMSO started publishing new legislation on the Web in 1996. Where HMSO and later OPSI provided access to legislation as it was enacted or made, a second service was developed, to provide access to the UK Statute Law Database. This contains revised versions of primary legislation, showing how they have changed over time.
Our research showed that many people using legislation online assume that what they are looking at is both current and in force, simply because it is on the Web and available from an official source. Often users were accessing the original or as-enacted version of a statute, not knowing that they should be looking at the revised version, or that a revised version even existed.
Intuitive presentation
Our job is to present legislative material in such a way that the context and status of the information are clear. Legislation is complicated to understand; for example, an Act may have multiple sections, each with a different commencement date, or the Act may have prospective provisions. With legislation.gov.uk we have tried to develop a user interface that makes the status of each Act clear, so people know whether the statute they are viewing is current and in force. The usability challenge is to align what people think they are seeing with what they are actually looking at. We have done this by presenting both an original (see, e.g., here) and a latest-available version (see, e.g., here) of each Act, and a toggle between the two.
For more advanced users there is a timeline (see, e.g., here) which can be turned on to see how the legislation has changed and to navigate through an Act at particular points in time, including future or prospective versions.
Open data
On the surface, legislation.gov.uk is an attractive Website, providing simple and direct access to legislation; at legislation.gov.uk people can view whole Acts, or a particular section, in either HTML (see, e.g., here) or in a print version in PDF (see, e.g., here). To achieve this, under the hood two very different sources of data have been combined. The data model for the original (or as-enacted) versions of legislation is largely driven by the typographic layout of legislative documents. For revised legislation, the data model is largely driven by version control, the management of multiple versions of different segments of a statute at different points in time. Reconciling these two different data models was a prerequisite step to developing our system.
We aimed to make legislation.gov.uk a source of open data from the outset. The importance of open legal data is made powerfully by people like Carl Malamud and the Law.Gov campaign. Our desire to make the statute book available as open data motivated a number of technology choices we made. For example, the legislation.gov.uk Website is built on top of an open Application Programming Interface (API). The same API is available for others to use to access the raw data.
Using the API
The simplest way to get hold of the underlying data on legislation.gov.uk is to go to a piece of legislation on the Website, either a whole item, or a part or section, and just append /data.xml or /data.rdf to the URL. So, the data for, say, Section 1 of the Communications Act 2003, which is at http://www.legislation.gov.uk/ukpga/2003/21/section/1, is available at http://www.legislation.gov.uk/ukpga/2003/21/section/1/data.xml. We have taken a similar approach with lists, both in browse and search results. When looking at any list of legislation on legislation.gov.uk, it is easy to view the data. Simply append /data.feed to return that list in ATOM. (See, e.g., here.)
Open standards have played an important role throughout the development of legislation.gov.uk. All the data is held in XML, using a native XML database. The application logic is similarly constructed using open standards, in XSLTs and XQueries. Data and application portability were key objectives. We made considerable use of open source software like Orbeon Forms, Squid, and Apache.
The XML conforms to the Crown Legislation Markup Language (CLML) and associated schema. More general interchange formats for legislation such as CEN MetaLex lack the expressive power we need for UK legislation, but could relatively easily be wrapped around the XML we are making available. We have sought to surface richer metadata about legislation using RDF, but we would welcome feedback from users of the XML data about whether a MetaLex wrapper would be useful. (Note: We have used the MetaLex vocabulary in our RDF along with FRBR, as discussed below.) Similarly, it should be relatively easy to add a wrapper for the OAI-PMH protocol on top of the API we have built. We are not yet clear who would make use of such a service, if we built one, or whether we should leave the creation of an OAI-PMH interface to others. It is another open issue where we would welcome some feedback.
Persistent URIs
A major influence on legislation.gov.uk was a blog posting by Rick Jelliffe for O’Reilly’s XML.com. Jelliffe writes about something he calls PRESTO. He describes this as a system for legislation and public information in which “all documents, views and metadata at all significant levels of granularity and composition should be available in the best formats practical from their own permanent hierarchical URIs.”
Persistent URIs to pieces of legislation are very important, as they are to sources of law more generally. Initiatives like LegisLink, which Joe Carmel has written about here, attempt to retrofit a reliable naming scheme for legislation onto existing document-based systems. The URN:LEX namespace aims to facilitate the process of creating URIs for legal sources independent of a documentÂ’s online availability, location, and access mode.
We wanted to create high quality, persistent URIs for UK legislation from the outset. There are a number of different ways one might assign an unequivocal identifier to a legislative document. We have decided to use HTTP URIs and see no particular advantage in using URNs over HTTP URIs and indeed some disadvantages with URNs. Most importantly, HTTP URIs are actionable names. The advantage is that there is a built-in, ready-made, widely deployed and cost-effective resolution mechanism for resolving the identifier to a document, and a document to a representation. Having said that, we would consider supporting URN:LEX URNs in addition to our own URI Set, and would greatly welcome feedback from the community on this issue -– so please do comment if you have a view.
So, it follows, there are three types of URI for legislation on legislation.gov.uk, namely, identifier URIs, document URIs and representation URIs. Identifier URIs are for the ‘concept’ of a piece of legislation, how it was, how it is, and how it will be. (See, e.g., here.) Our use of these follow the Linked Data principles — the identifier URI is for a so-called non-information resource, something which can’t be conveyed in an electronic message. In other words, the URI is for the notion of a piece of legislation, rather than a particular rendition of it in a document. These URIs have been designed following the guidelines the UK Government has created for URI Sets, which our work helped to shape.
With legislation.gov.uk we support content negotiation, and follow the HTTP-Range 14 resolution approach, of responding to a request for the ‘non-information resource’ URI with a 303 response which redirects to a document URI.
Our document URIs refer to particular documents on the Web, for example the current, in-force version of a particular section of an Act. (See, e.g., here.) Crucially there are also point-in-time URIs for documents, which shows how that Act stood on a particular date (/yyyy-mm-dd) (see, e.g., here), or how it was when originally made (/enacted) (see, e.g., here). For any document we can return different representations or formats: a Web page on legislation.gov.uk, the underlying XML, a PDF, an HTML snippet, or even some RDF metadata. We recommend that people cite UK legislation in HTML by pointing to the identifier URI and by using the rel=”cite” attribute in the anchor tag.
Of course, we quickly discovered, it is one thing to suggest a design approach like PRESTO, and quite another to actually implement it. Jeni Tennison, who, working as a consultant to The Stationery Office, devised the URI Set for legislation (and much else about the legislation.gov.uk system), has blogged about the limitations of PRESTO and XPath-based URLs. I hope Jeni will find the time to blog some more about legislation.gov.uk, as there are many stories to be told.
One of the earliest pieces of design work we did for legislation.gov.uk was the URI Set. We wanted to follow PRESTO principles, but also account for changes over time, and for some of the peculiarities of UK legislation, in particular different geographic extents. (See, e.g., here.) PRESTO thinking is very evident on legislation.gov.uk; just look at the URLs as you move through the site.
Linked Data
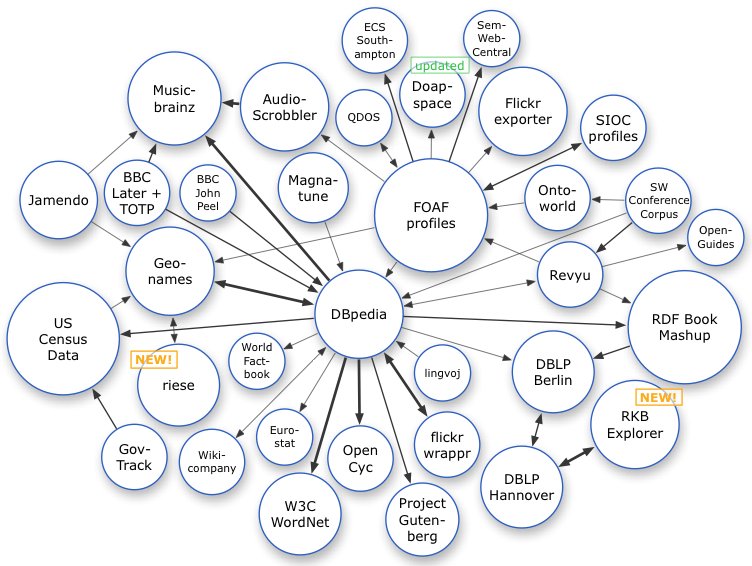 We were also keen that the UK’s Statute Book make a contribution to the growing Web of Linked Data. The UK government is working hard to publish government data using Linked Data standards as part of work on data.gov.uk. The idea of the Web of Linked Data is to connect related information across the Web based on its meaning. In practice this means creating names for things (by ‘thing’ I mean anything: people, places, ideas) using HTTP, and when someone requests some information about that thing, returning data about it, ideally using RDF.
We were also keen that the UK’s Statute Book make a contribution to the growing Web of Linked Data. The UK government is working hard to publish government data using Linked Data standards as part of work on data.gov.uk. The idea of the Web of Linked Data is to connect related information across the Web based on its meaning. In practice this means creating names for things (by ‘thing’ I mean anything: people, places, ideas) using HTTP, and when someone requests some information about that thing, returning data about it, ideally using RDF.
Legislation can make an important contribution to the Web of Linked Data. First, many important concepts and ideas are formally defined by statute. For example, there are 27 types of school in the UK and each one has a statutory definition. (See, e.g., here and here.) What it means to be a private limited company is again defined by statute, as are the UKÂ’s eight data protection principles. One of our objectives with legislation.gov.uk is to enable people creating vocabularies and ontologies to exploit these definitions. This can be done, for example, by using the skos:definition property, to link terms in a vocabulary to the statute. The idea is to ease the process of rooting the Semantic Web in legally defined concepts. Part of the value of this linking is that it enables automatic checking to determine whether a part of the statute book has been repealed, in which case the related concept no longer exists. Crucially, legislation.gov.uk gives accurate information about when a section is repealed, by what piece of legislation, and when that repeal comes into force.
At the moment, the RDF from legislation.gov.uk is limited to largely bibliographic information. We have made use of the Functional Requirements for Bibliographic Records (FRBR) and the MetaLex vocabularies, primarily to relate the different types of resource we are making available. FRBR has the notion of a work, expressions of that work, manifestations of those expressions, and items. Similarly, MetaLex has the concepts of a BibliographicWork and BibliographicExpression. In the context of legislation.gov.uk, the identifier URIs relate to the work. Different versions of the legislation (current, original, different points in time, or prospective) relate to different expressions. The different formats (HTML, HTML Snippets, XML, and PDF) relate to the different manifestations. We have also made extensive use of Dublin Core Terms, for example to reflect that different versions apply to geographic extents. This is important as, for example, the same section of a statute may have been amended in one way as it applies in Scotland and in another way for England and Wales. We think FRBR, MetaLex, and Dublin Core Terms have all worked well, individually and in combination, for relating the different types of resource that we are making available.
One challenge we have is with changes to legislation that have yet to be applied to the data by the editorial team. Since we know what these effects are, we have also tried to represent this in RDF. We have used the MetaLex vocabulary to do this, but the result is complicated to interpret, and thus we suspect difficult for users of the data. MetaLex does not aid the elegant expression of amendment information (such as: statute A is changed by statute B, but only when commencement order C brings that change into force). We will be developing our own light-weight ontology for expressing some of these relationships, with the primary focus on ease of querying our data, rather than creating an ontology with the expressive power to be a cross-jurisdictional model.
It should then be possible to align this ontology with others post hoc. Our current use of RDF — and the potential to do more — is another issue where we would welcome feedback from the community.
Early adopters
People have already started to make use of the legislation.gov.uk URIs to support their Linked Data. One example is a project by ESD Toolkit. They have a created a SKOS vocabulary for all the different types of service that Local Authorities need to provide. They have linked this vocabulary to the powers and duties placed on Local Authorities in the legislation, using legislation.gov.uk identifier URIs. They have also used the API to pull back some of the text of the relevant statutes.
The future
We think there is huge potential over the next few years in the development of “accountable systems”. These are systems that are explicitly aware of statutory and other legal requirements and are able to process information explicitly in a way that complies with the (ever-changing) law. Here the legislation URIs can help enormously, either for people seeking to develop such accountable systems or any time someone wants to integrate an external system with the official source for statutory information. If the API is used in this way, we will need to consider carefully whether, and if so, how, the data is authenticated. We are not currently supplying digitally signed versions of UK legislation (unlike the GPO in the US) but we will be supporting the use of HTTPS, to provide a reasonable level of secure access to the data. However, if the data starts to be increasingly used in a new generation of accountable systems, we may need to address authenticity, with a view to increasing the guarantees we can make over the data.
There is much more we can do with legislation as data. Parts of the statute book are surprisingly well structured. For example, every year there is one or more Appropriation Acts. These typically contain a schedule with a table listing each government department, the amount allocated to it by Parliament for the year, and what that departmentsÂ’ objectives are (see, e.g., here). It wouldnÂ’t take much to create an XSLT just for these tables in the Appropriation Acts, from the XML provided from the API, to extract this data from all the Appropriation Acts, and publish that as Linked Data. There are many other examples of almost-structured data in legislation, waiting to be freed by developers, now that they have easy access to the underlying source.
We see this as a start. There is still much to do if we are to realise the potential of the statute book as public source of data. We are aiming to improve the modelling and the quantity of RDF data we make available about legislation, but itÂ’s what others will do with the data that is really interesting. Now the UK has opened its statute book as Linked Data, we are keen to share our work with other governments, and to engage with academics in the legal informatics community and others with an interest in exploiting this rich source of information.
Legislinks
From: http://blog.law.cornell.edu/voxpop/2010/07/15/legislinkorg-simplified-human-readable-urls-for-legislative-citations/
The Problem: URLs and Internal Links for Legislative Documents
Legislative documents reside at various government Websites in various formats (TXT, HTML, XML, PDF, WordPerfect). URLs for these documents are often too long or difficult to construct. For example, here is the URL for the HTML format version of bill H.R. 3200 of the 111th U.S. Congress:
http://www.gpo.gov/fdsys/pkg/BILLS-111hr3200IH/html/BILLS-111hr3200IH.htm
More importantly, “deep” links to internal locations (often called “subdivisions” or “segments”) within a legislative document (the citations within the law, such as section 246 of bill H.R. 3200) are often not supported, or are non-intuitive for users to create or use. For most legislative Websites, users must click through or fill out forms and then scroll or search for the specific location in the text of legislation. This makes it difficult if not impossible to create and share links to official citations. Enabling internal links to subdivisions of legislative documents is crucial, because in most situations, users of legal information need access only to a subdivision of a legal document, not to the entire document.
A Solution: LegisLink
LegisLink.org is a URL Redirection Service with the goal of enabling Internet access to legislative material using citation-based URLs rather than requiring users to repeatedly click and scroll through documents to arrive at a destination. Let’s say you’re reading an article at CNN.com and the article references section 246 in H.R. 3200. If you want to read the section, you can search for H.R. 3200 and more than likely you will find the bill and then scroll to find the desired section. On the other hand, you can use something like LegisLink by typing the correct URL. For example: http://legislink.org/us/hr-3200-ih-246.
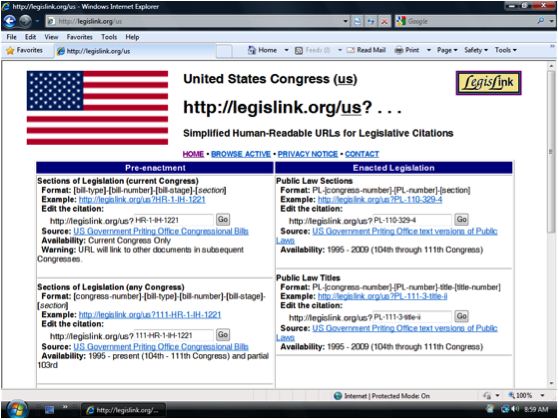
Benefits
There are several advantages of having a Web service that resolves legislative and legal citations.
(1)  LegisLink provides links to citations that are otherwise not easy for users to create. In order to create a hyperlink to a location in an HTML or XML file, the publisher must include unique anchor or id attributes within their files. Even if these attributes are included, they are often not exposed as links for Internet users to re-use.  On the other hand, Web-based software can easily scan a file’s text to find a requested citation and then redirect the user to the requested location. For PDF files, it is possible to create hyperlinks to specific pages and locations when using the Acrobat plug-in from Adobe. In these cases, hyperlinks can direct the user to the document location at the official Website.
For example, here is the LegisLink URL that links directly to section 246 within the PDF version of H.R. 3200: http://legislink.org/us/hr-3200-ih-246-pdf
In cases where governments have not included ids in HTML, XML or TXT files, LegisLink can replicate a government document on the LegisLink site, insert an anchor, and then redirect the user to the requested location.
(2)  LegisLink makes it easy to get to a specific location in a document, which saves time.  Law students and presumably all law professionals are relying on online resources to a greater extent than ever before. In 2004, Stanford Law School published the results of their survey that found that 93% of first year law students used online resources for legal research at least 80% of the time.
(3)  Creating and maintaining a .org site that acts as an umbrella for all jurisdictions makes it easier to locate documents and citations, especially when they have been issued by a jurisdiction with which one is unfamiliar. Legislation and other legal documents tend to reside at multiple Websites within a jurisdiction. For example, while U.S. federal legislation (i.e., bills and slip laws) is stored at thomas.loc.gov (HTML and XML) and gpo.gov (at FDsys and GPO Access) (TXT and PDF), the United States Code is available at uscode.house.gov and at gpo.gov (FDsys and GPO Access), while roll call votes are at clerk.house.gov and www.senate.gov.  Governments tend to compartmentalize activities, and their Websites reflect much of that compartmentalization. LegisLink.org or something like it could, at a minimum, provide a resource that helps casual and new users find where official documents are stored at various locations or among various jurisdictions.
(4) LegisLinks won’t break over time. Governments sometimes change the URL locations for their documents. This often breaks previously relied-upon URLs (a result that is sometimes called “link rot”). A URL Redirection Service lessens these eventual annoyances to users because the syntax for the LegisLink-type service remains the same. To “fix” the broken links, the LegisLink software is simply updated to link to the government’s new URLs. This means that previously published LegisLinks won’t break over time.
(5)  A LegisLink-type service does not require governments to expend resources. The goal of LegisLink is to point to government or government-designated resources. If those resources contain anchors or id attributes, they can be used to link to the official government site. If the documents are in PDF (non-scanned), they can also be used to link to the official government site. In other cases, the files can be replicated temporarily and slightly manipulated (e.g., the tag <a name=SEC-#> can be added at the appropriate location) in order to achieve the desired results.
Alternatives
While some Websites have implemented Permalinks and handle systems (e.g., the Library of CongressÂ’s THOMAS system), these systems tend to link users to the document level only. They also generally only work within a single Internet domain, and casual users tend not to be aware of their existence.
Other technologies at the forefront of this space include recent efforts to create a URN-based syntax for legal documents (URN:LEX). To quote from the draft specification, “In an on-line environment with resources distributed among different Web publishers, uniform resource names allow simplified global interconnection of legal documents by means of automated hypertext linking.”
The syntax for URN:LEX is a bit lengthy, but because of its specificity, it needs to be included in any universal legal citation redirection service. The inclusion of URN:LEX syntax does not, however, mitigate the need for additional simpler syntaxes. This distinction is important for the users who just want to quickly access a particular legislative document, such as a bill that is mentioned in a news article.  For example, if LegisLink were widely adopted, users would come to know that the URL http://legislink.org/us/hr-3200 will link to the current Congress’s H.R. 3200; the LegisLink URL is therefore readily usable by humans. And use of LegisLink for a particular piece of legislation is to some extent consistent with the use of URN:LEX for the same legislation: for example, a URN:LEX-based address such as http://legislink.org/urn:lex/us/federal:legislation:2009; could also lead to the current Congress’s H.R. 3200. A LegisLink-type service can include the URN:LEX syntax, but the URN:LEX syntax cannot subsume the simplified syntax being proposed for LegisLink.org.
111.hr.3200@official;thomas.loc.gov:en$text-html
The goals of Citability.org, another effort to address these issues, calls for the replication of all government documents for point-in-time access. In addition, Citability.org envisions including date and time information as part of the URL syntax in order to provide access to the citable content that was available at the specified date and time. LegisLink has more modest goals: it focuses on linking to currently provided government documents and locations within those documents. Since legislation is typically stored as separate, un-revisable documents for a given legislative term (lasting 2 years in many U.S. jurisdictions), the use of date and time information is redundant with legislative session information.
The primary goal of a legislative URL Redirection Service such as LegisLink.org is to expedite the delivery of needed information to the Internet user. In addition, the LegisLink tools used to link to legislative citations in one jurisdiction can be re-used for other jurisdictions; this reduces developersÂ’ labor as more jurisdictions are added.
Next Steps
The LegisLink.org site is organized by jurisdiction: each jurisdiction has its own script, and all scripts can re-use common functions. The prototype is currently being built to handle the United States (us), Colorado (us-co), and New Zealand (nz). The LegisLink source code is available as text files at http://legislink.org/code.html.
The challenges of a service like LegisLink.org are: (1) determining whether the legal community is interested in this sort of solution, (2) finding legislative experts to define the needed syntax and results for jurisdictions of interest, and (3) finding software developers interested in helping to work on the project.
This project cannot be accomplished by one or two people. Your help is needed, whether you are an interested user or a software developer. At this point, the code for LegisLink is written in Perl. Please join the LegisLink wiki site at http://legislink.wikispaces.org to add your ideas, to discuss related information, or just to stay informed about whatÂ’s going on with LegisLink.
Metalex
From:http://blog.law.cornell.edu/voxpop/2011/10/25/the-metalex-document-server/
In this post I describe the process and requirements that eventually led to the MetaLex Document Server, a server that hosts all versions of Dutch national statutes and regulations published since May 2011, both as CEN MetaLex, and as Linked Data. Before I set out to do so, however, I would like to emphasize that, although the development of the server and its contents was a one-man-job, the road to make it possible surely was not solitary. A couple of people I’d like to mention here are Alexander Boer, Radboud Winkels, and Tom van Engers of the Leibniz Center for Law, together with whom I have worked over the past ten years to develop, test, and publish the ideas that underlie CEN MetaLex. Also, the team around legislation.gov.uk clearly has done a lot of great and inspiring work in this area.
So, what happened? Over the course of last spring, I was involved in several small-scale projects that shared a specific need: version-aware identifiers for all parts of legislative texts.  The first of these was a report for the Swiss Federal Chancellery on possible technological solutions for a regulation drafting system to be used by the Swiss government. Second to arrive on my desk was a project for the Dutch Tax and Customs Administration (Belastingdienst), in which we were asked to develop a concept-extraction toolkit that would allow them to make explicit where concepts are defined, where they are reused, and how they relate to other concepts (e.g., from an external thesaurus). The purpose of this project was to investigate whether we could replace with technology what is currently a manual process of turning legislation into business processes that fuel citizen- and business-oriented services. The Belastingdienst needs this to better cope with the yearly changes to tax regulation issued by the Ministry of Finance. The Dutch Immigration and Naturalisation Service (IND) faces exactly the same problem: of discovering what part of their business processes is affected by each legislative modification. Updates to legislation require continuous, significant investment in IT re-engineering.
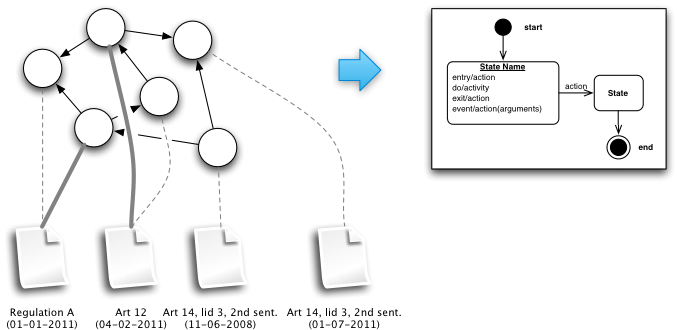
The root of the problem
But donÂ’t modern European governments already have elaborate facilities for supporting this workflow? IÂ’m afraid not.
Currently, regulation drafting is a process of sending around Word documents, copy-and-pasting from older texts, “version hell,” signing by a Minister, and sending the enacted regulations off to a publisher, who will then turn it into some XML format to feed a publishing platform to generate HTML, PDF, and paper versions of the texts. This process is not designed with a content management perspective, and most if not all metadata is thrown away in the process.
Part of the problem is one of organisational change: convincing legislative drafters to use a more structured approach in their daily work. The Dutch Ministry of Security and Justice is currently developing a legislative editing environment (similar to the MetaVex editor developed at the University of Amsterdam), but it will take awhile before this is adopted in practice.
Requirements
To develop a chain of tools for managing legal information, both as text and as knowledge models, we need to address a number of key requirements:
- An integrated legislative drafting and editing environment that supports advanced version and provenance tracking (e.g., version tracking of successive changes to draft texts). Provenance information is very important for eliciting the procedure that led to an official version (both pre- and post-publication), as well as its underlying motivation.
- A format in which these texts are stored that is flexible enough to allow both editing and publication to various formats (such as PDF and HTML).
- The ability to persistently identify every element of a legal text. Versioning of texts, references, and metadata requires identifiers that reflect the different versions of these resources. The various parts of a text should be versioned independently, allowing for transitory regimes.
A versioning mechanism should distinguish between a regulation text as it exists at a particular time, and the final regulation. The IFLA Functional Requirements for Bibliographic Records (FRBR) (Saur, ’98) makes the following distinctions: the work as a “distinguishable intellectual or artistic creation” (e.g., the constitution); the expression as the “intellectual or artistic form that a work takes each time it is realised” (e.g., “The Constitution of July 15th, 2008?); the manifestation as the “physical embodiment of an expression of a work” (e.g., a PDF version of “The Constitution of July 15th, 2008?); and the item as a “single exemplar of a manifestation” (e.g., the PDF version of “The Constitution of July 15th, 2008? residing on my USB stick).
- These identifiers should be dereferenceable to the element they describe, or a description of the elementÂ’s metadata.
- Metadata and annotations should be traceable to the most detailed part of a text, as well as to its version, when needed. The same requirement holds for references between texts, allowing for fine-grained analysis of interdependencies between texts.
- It is furthermore a requirement that these identifiers be transparent and follow a prescribed naming convention. This allows third parties to construct valid identifiers without having to first query a name service.
- The metadata itself should be made accessible in a standard format as well.
Making do with what weÂ’ve got
As we donÂ’t have any time to waste, and have neither the organisational infrastructure, nor the funds, to use or develop any other (richer) information source, we need to make do with whatÂ’s currently available. How hard is it to build a chain of tools that meets at least part of these requirements? And, what information does the Dutch government already provide on which we can build the services that it itself so dearly needs?

Wetten.overheid.nl is the de facto source for legislative information in The Netherlands. Users can perform a full text search through the titles and text of all statutes and regulations of the Kingdom of the Netherlands. They can search for a specific article, as well as for the version of a text as it stood at a specified date. Wetten.overheid.nl also provides an API for retrieving XML manifestations of statutes and regulations.
Identifiers
What about identifiers? Wetten.nl supports deeplinks to particular versions of statutes and regulations, but is not very consistent about it. For example:
http://wetten.overheid.nl/cgi-bin/deeplink/law1/bwbid=BWBR0005416/article=6/date=2005-01-14
and
both point to article 6 of the Municipal law, as it was in effect on January 14th, 2005. A third mechanism for identifying regulations is the Juriconnect standard for referring to parts of statutes and regulations. XML documents hosted by Wetten.nl use these identifiers to specify citations between statutes and regulations. For instance, the Juriconnect identifier for article 6 of the Municipal law is:
1.0:c:BWBR0005416&artikel=16&g=2005-01-14
ButÂ… the standard does not prescribe a mechanism for dereferenecing an identifier to the actual text of (part of) a statute or regulation.
The BWB XML service and format
XML manifestations of statutes and regulations are retrievable through an API on top of the “Basiswettenbestand” (BWB) content management system. This REST Web service only provides the latest version of an entire statute or regulation. The BWB XML document returned is stripped of all version history: it does not even contain the version date of the text itself.
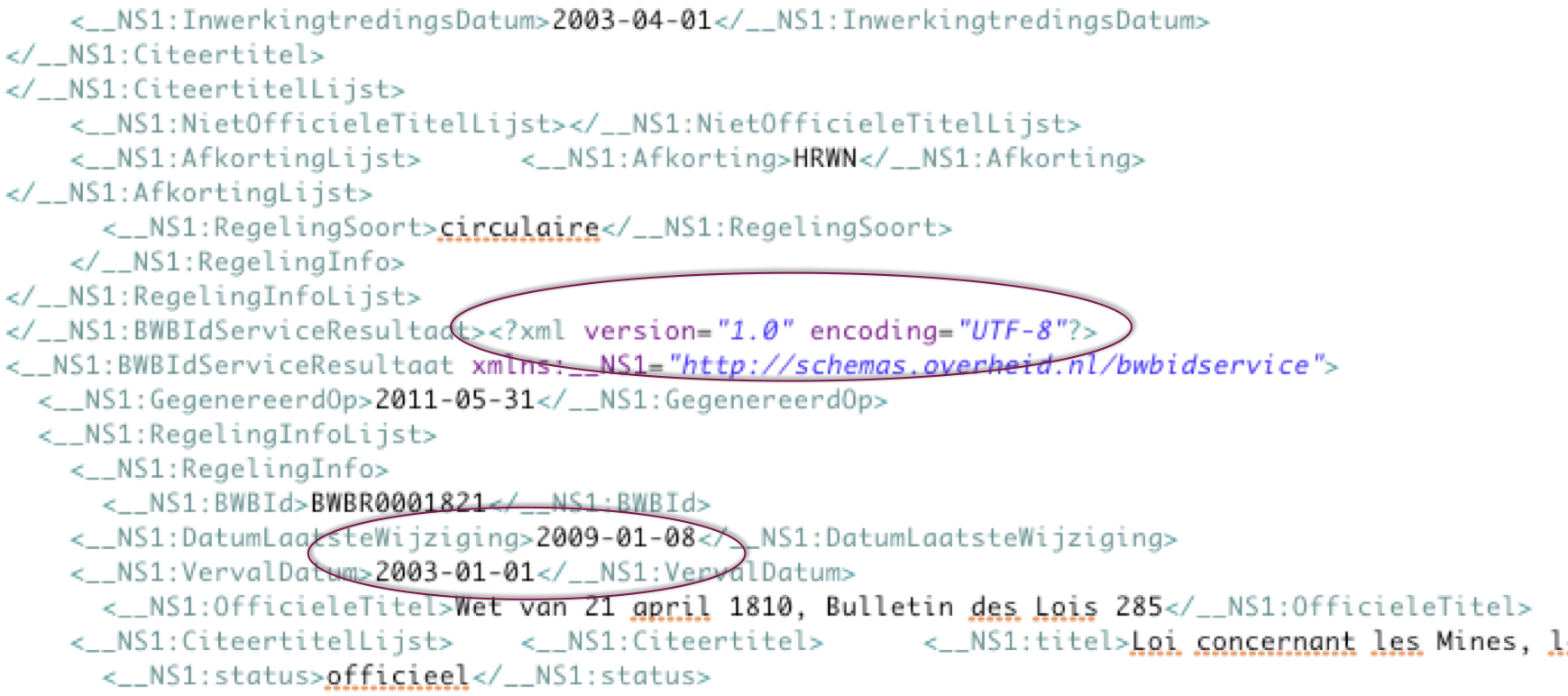
An index of all BWB identifiers, with basic attributes such as official and abbreviated titles, enactment and publication dates, retroactivity, etc. is available as a zipped XML dump or a SOAP service. Unfortunately, the XML file is corrupt, and the date of the latest change to a statute or regulation reported in the index is not really the date of the latest modification, but of the latest update of the statute or regulation in the CMS.  See the picture above.
The BWB uses its own XML schema for storing statutes and regulations; this schema does not allow for intermixing with any third-party elements or attributes, ruling out obvious extensions for rich annotations such as RDFa. And, BWB XML elements do not carry any identifiers.
A more general XML format: CEN MetaLex
CEN MetaLex is a jurisdiction-independent XML format for representing, publishing, and interchanging legal texts. It was developed to allow traceability of legal knowledge representations to their original source. MetaLex elements are purely structural. Syntactic elements (structure) are strictly distinct from the meaning of elements by specifying for each element a name and its content model. What this essentially does is to pave the way for a semantic description of the types of content of elements in an XML document. The standard prescribes the existence of a naming convention for minting URI-based identifiers for all structural elements of a legal document. MetaLex explicitly encourages the use of RDFa attributes on its elements, and provides special metadata-elements for serialising additional RDF triples that cannot be expressed on structural elements themselves. MetaLex includes an ontology, which defines an event model for legislative modifications. The legislation.gov.uk portal has adopted the MetaLex event model for representing modifications.
Getting from BWB to CEN MetaLex
The MetaLex schema is designed to be independent of jurisdiction, which means that it should be possible to map each legacy XML element to a MetaLex element in an unambiguous fashion. Fortunately, we were able to define a straightforward 1:n mapping between BWB and MetaLex (see below) by a semi-automatic conversion of the BWB XML DTD.
The transformation of legacy XML to MetaLex and RDF is implemented in the MetaLex converter, an open source Python script available from GitHub. Conversion occurs in four stages:
- mapping legacy elements to MetaLex elements,
- minting identifiers for newly created elements,
- producing metadata for these elements, and
- serialising to appropriate formats.
Step 1: Mapping
For the transformation of BWB XML files, the converter is sequentially fed with all BWB XML files and identifiers listed in the BWB ID index. Based on the mapping table, the converter traverses the DOM tree of the source document, and synchronously builds a DOM tree for the target document. In cases where the MetaLex schema doesn’t quite “fit,” the converter has to make additional repairs.
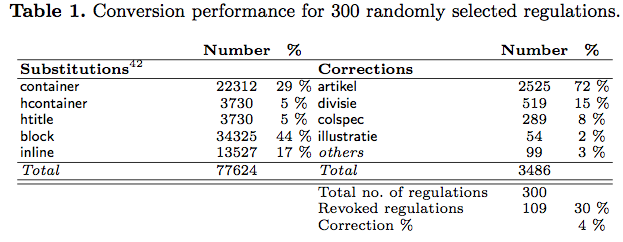
We evaluated the ability of MetaLex to map onto the BWB XML by running the converter on 300 randomly selected BWB identifiers. The artikel element accounts for 72% of all corrections, and corresponds to 68% of all htitle substitutions (5 % of total). This means that only a very small part of BWB XML does not directly fit onto the MetaLex schema. The main cause for incompatibility is the restriction in MetaLex that hcontainer elements are not allowed to contain block elements (and that’s perhaps something to consider for the MetaLex workshop).
Because of the limitations of the API, version information, citation titles, and other metadata are retrieved through a custom-built scraper of the information pages on the wetten.nl Website.
Step 2: Minting Identifiers
For every element in the document we create transparent URL-like URIs for the work, expression and manifestation levels, and two opaque URIs for the expression and item levels in the FRBR specification.
For transparent URIs, we use a naming scheme that is based on the URIs used at legislation.gov.uk, with slight adaptations to allow for the Dutch situation. In short, work level identifiers are based on the standard BWB identifier, followed by a hierarchical path to an element in the source, e.g., “chapter/1/article/1?. These URIs are extended to expression URIs by appending version and language information. Similarly, manifestation URIs are extensions of expression URIs that specify format information such as XML, RDF, etc. Juriconnect references in the source BWB XML are automatically translated to this naming scheme.
The opaque version URI is needed to distinguish different versions of a text. The current Webservice does not provide access to all versions of statutes and regulations (only to the latest), let alone at a level of granularity lower than entire statutes or regulations. We therefore need some way of constructing a version history by regularly checking for new versions, and comparing them to those we looked at before. By including in the opaque URI a unique SHA1 hash of the textual content of an XML element, and simultaneously maintaining a link between the opaque URI and the transparent identifier, different expressions of a work can be automatically distinguished through time. This is needed to work around issues with identifiers based on numbers: the insertion of a new element can change the position (and therefore the identifier) of other elements without a change in the content of the elements.
By this method, globally persistent URIs of every element in a legal text can be consistently generated for both current and future versions of the text. By simultaneously generating an opaque and a transparent expression level URI, identification of these text versions does not have to rely on numbering.
Step 3: Producing Metadata
The MetaLex converter produces three types of metadata. First, legacy metadata from attributes in the source XML is directly translated to RDF triples. Second, metadata describing the structural and identity relations between elements is created. This includes typing resources according to the MetaLex ontology, e.g., as ml:BibliographicExpression; creating ml:realizes relations between expressions and works; and creating owl:sameAs relations between opaque and transparent expression URIs. The official title, abbreviation, and publication date of statutes and regulations are represented using the dcterms:title, dcterms:alternative and dct:valid properties.
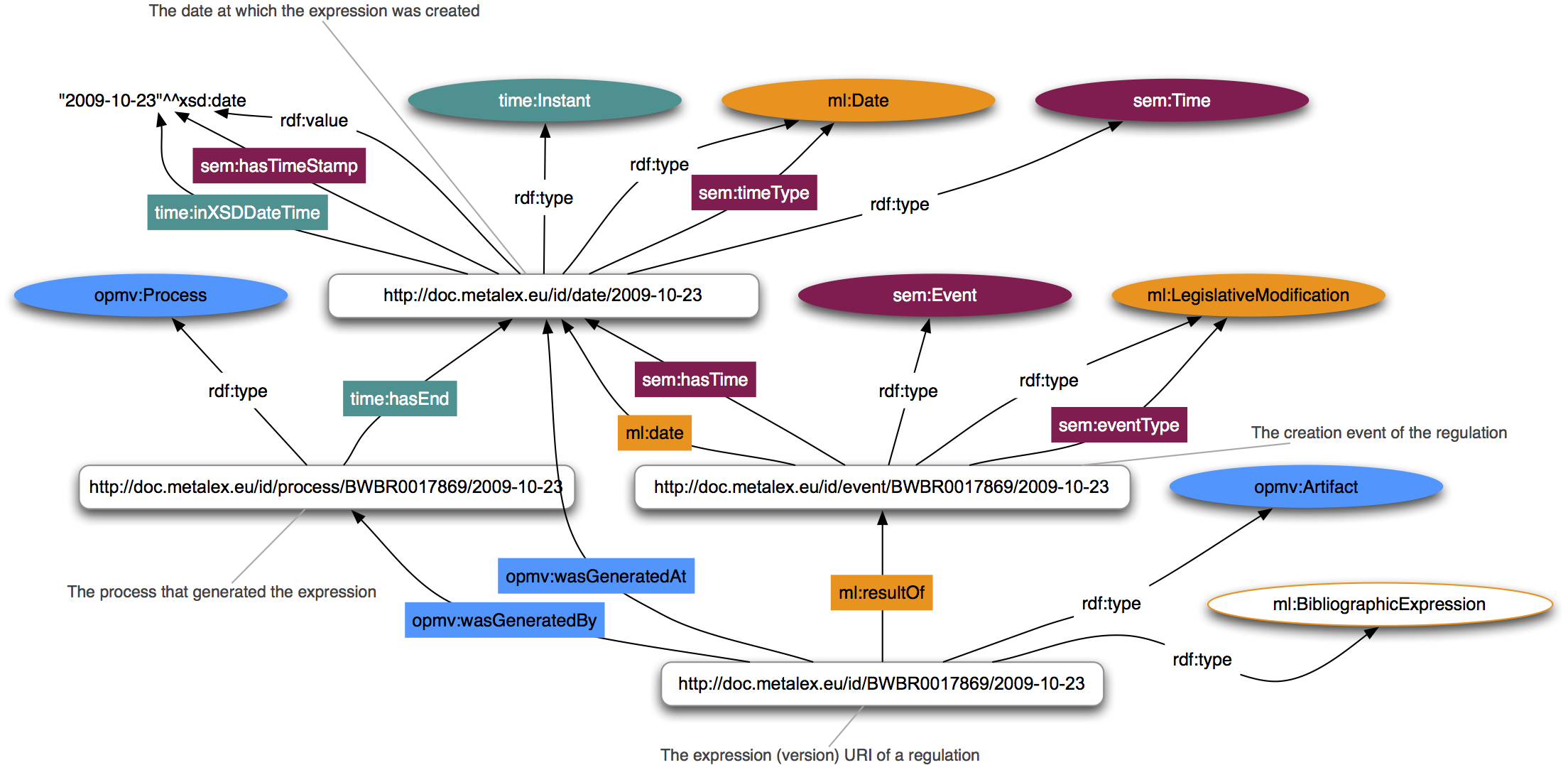
Events and Processes
Event information plays a central role in determining what version of a regulation was valid when. Making explicit which events and modifying processes contributed to an expression of a regulation provides for a flexible and extensible model. The MDS uses the MetaLex ontology for legislative modification events, the Simple Event Model (SEM) and the W3C Time Ontology for an abstract description of events and event types, and the Open Provenance Model Vocabulary (OPMV) for describing processes and provenance information. These vocabularies can be combined in a compatible fashion, allowing for maximal reuse of event and process descriptions by third parties that may not necessarily commit to the MetaLex ontology.

Step 4: Serialization
The MetaLex converter supports three formats for serialising a legal text to a manifestation: the MetaLex format itself, viewable in a browser by linking a CSS stylesheet; RDFa, Turtle and RDF/XML serializations of the RDF metadata; and a citation graph. The converter can automatically upload RDF to a triple store through either the Sesame API, or SPARQL updates. The citation graph is exported as a ‘”net” network file, for further analysis in social network software tools such as Pajek and Gephi. We are exploring ways to use these networks for determining the importance of articles (in degree) and the dependency of legislation on certain articles (betweenness centrality), and for analysing the correlation between legislation and case law.
Publication
The results of this procedure are published through the MetaLex Document Server (MDS). The server follows the Cool URIs specification, and implements HTTP-based redirects for work- and expression-level URIs to corresponding manifestations based on the HTTP accept header. Requests for an HTML mime-type are redirected to a Marbles HTML rendering of a Symmetric Concise Bounded Description (SCBD) of the RDF resource. Similarly, requests for RDF content return the SCBD itself; supported formats are RDF/XML and Turtle. A request for XML will return a snippet of MetaLex for the specified part of a statute or regulation.
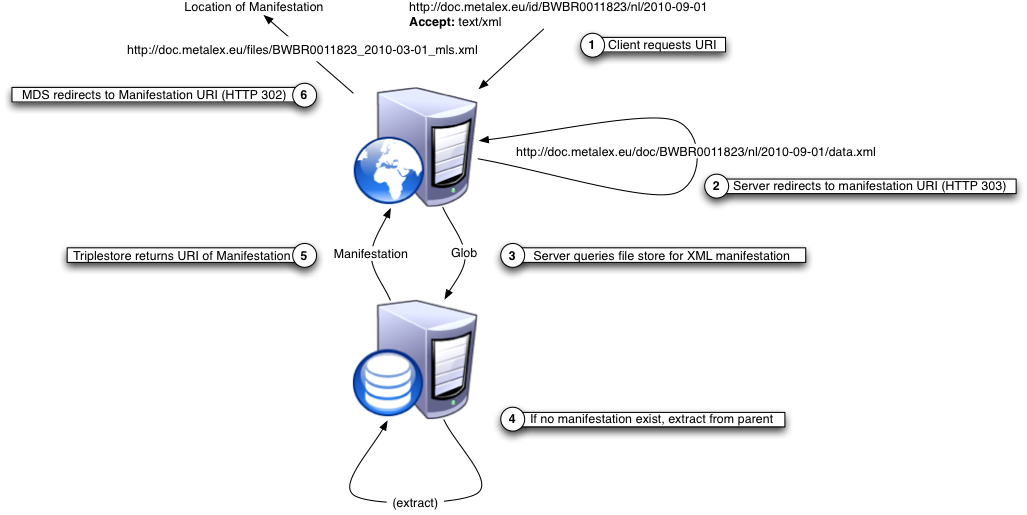
The MDS provides two convenient methods for retrieving manifestations of a statute or regulation. Appending “/latest” to a work URI will redirect to the latest expression present in the triple store. Appending an arbitrary ISO date will return the last expression published before that date if no direct match is available. Lastly, the MDS offers a simple search interface for finding statutes and regulations based on the title and version date.
Results and Take Up
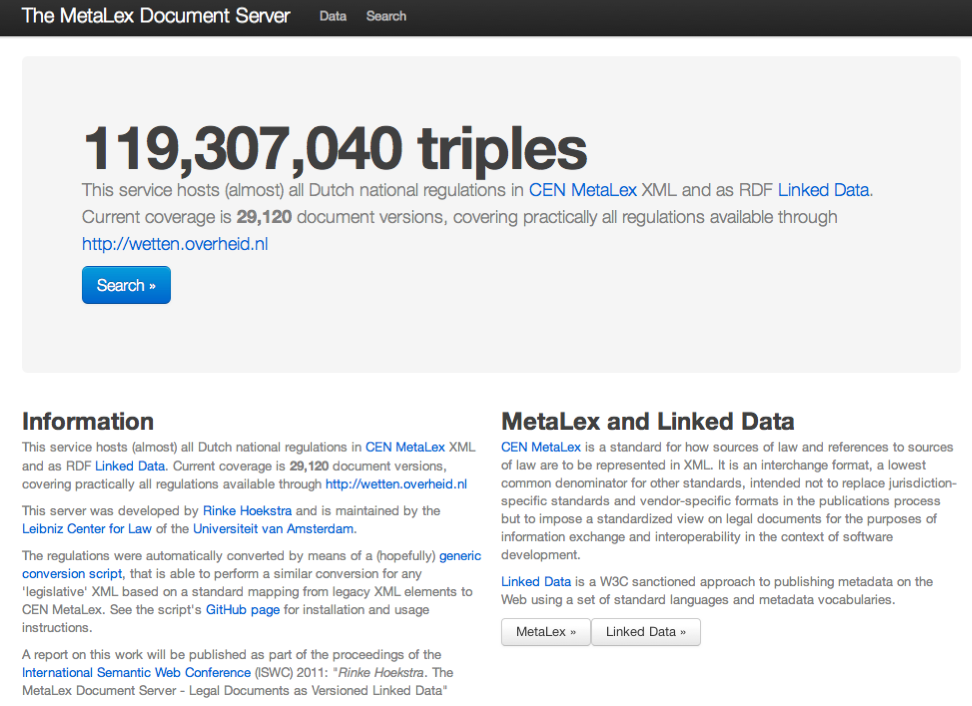 We have been running the converter on a daily basis, on all versions of statutes and regulations made available through the wetten.nl portal since May 2011. This has resulted in a current total of 29,120 document versions: 28 thousand versions in the first run, the rest accumulated through time. For these document versions, we now store 119 million triples of RDF metadata in a 4Store triple store. Compared to the size of legislation.gov.uk (1.9 billion triples, since the 1200s), this is a modest number, but at the current growth rate we will soon need to look for alternative (more professional) solutions. Check the http://doc.metalex.eu Website for the latest numbers.
We have been running the converter on a daily basis, on all versions of statutes and regulations made available through the wetten.nl portal since May 2011. This has resulted in a current total of 29,120 document versions: 28 thousand versions in the first run, the rest accumulated through time. For these document versions, we now store 119 million triples of RDF metadata in a 4Store triple store. Compared to the size of legislation.gov.uk (1.9 billion triples, since the 1200s), this is a modest number, but at the current growth rate we will soon need to look for alternative (more professional) solutions. Check the http://doc.metalex.eu Website for the latest numbers.
I am happy to say, also, that this work has not gone unnoticed. The IND was particularly enthused by the versioning mechanism, and is in the process of adopting the MDS approach as their internal content management system. Similarly, the ability to link concept descriptions to reliably versioned parts of legislation has been an eye opener for the Belastingdienst. We are also in touch with several people at ICTU, the organisation behind Wetten.nl, to help them improve their services.
Leave a Reply